
Apache Cassandra는 확장성이 뛰어난 오픈소스 NoSQL 데이터베이스이다.
- 여러 데이터 센터 및 클라우드에서 대량의 정형, 반정형 및 비정형 데이터를 관리하는 데 적합
- 최대한의 유연성과 빠른 응답 시간을 위해 설계된 강력한 동적 데이터 모델과 함께 단일 장애 지점없이 많은 상용 서버에서 지속적인 가용성, 선형 확장성 및 운영 단순성을 제공
Cassandra 동작 원리
Cassandra의 확장형 아키텍처는 초당 페타 바이트의 정보와 수천 명의 동시 사용자 / 작업을 처리 할 수 있음을 의미한다.
Cassandra는 분할된 행 저장소 데이터베이스이다.
Cassandra의 아키텍처를 사용하면 권한이 있는 모든 사용자가 모든 데이터 센터의 모든 노드에 연결하고 CQL 언어를 사용하여 데이터에 액세스 할 수 있다. 사용 편의성을 위해 CQL은 SQL과 유사한 구문을 사용한다. Cassandra와 상호작용하는 가장 기본적인 방법은 CQL 셸인 cqlsh를 사용하는 것이다. cqlsh를 사용하면 키스페이스 및 테이블을 만들고 테이블을 삽입 및 쿼리하는 등의 작업을 수행 할 수 있다. 이 Cassandra 릴리스는 Cassandra 2.2 이상용 CQL에서 작동한다. 그래픽 도구를 선호하는 경우 DataStax DevCenter를 사용할 수 있다 . 생산을 위해 DataStax는 다양한 드라이버를 제공한다. 따라서 CQL 문이 클라이언트에서 클러스터로 전달 될 수 있다.
| CQL (Cassandra Query Language) 은 Cassandra DBMS에 대한 기본 인터페이스이다. CQL을 사용하는 것은 SQL (Structured Query Language)을 사용하는 것과 유사하다. CQL과 SQL은 열과 행으로 구성된 테이블의 동일한 추상 아이디어를 공유한다. SQL과의 주요 차이점은 Cassandra가 조인 또는 하위 쿼리를 지원하지 않는다는 것이다. 대신 Cassandra는 스키마 수준에서 지정된 컬렉션 및 클러스터링과 같은 CQL 기능을 통해 비정규 화를 강조한다. |
자동 데이터 배포
Cassandra는 링 또는 데이터베이스 클러스터에 참여하는 모든 노드에 자동 데이터 배포를 제공한다. 데이터는 클러스터의 모든 노드에 투명하게 분할되므로 개발자 또는 관리자가 클러스터에 데이터를 배포하기 위해 수행하거나 코딩해야하는 프로그래밍 방식이 없다.
기본 제공 및 사용자 지정 가능한 복제
Cassandra는 또한 Cassandra 링에 참여하는 노드간에 데이터의 중복 복사본을 저장하는 기본 제공 및 사용자 지정 가능한 복제를 제공한다. 즉, 클러스터의 노드가 다운되면 해당 노드의 데이터에 대한 하나 이상의 복사본을 클러스터의 다른 시스템에서 사용할 수 있다. 복제는 하나의 데이터 센터, 여러 데이터 센터 및 여러 클라우드 가용성 영역에서 작동하도록 구성 할 수 있다.
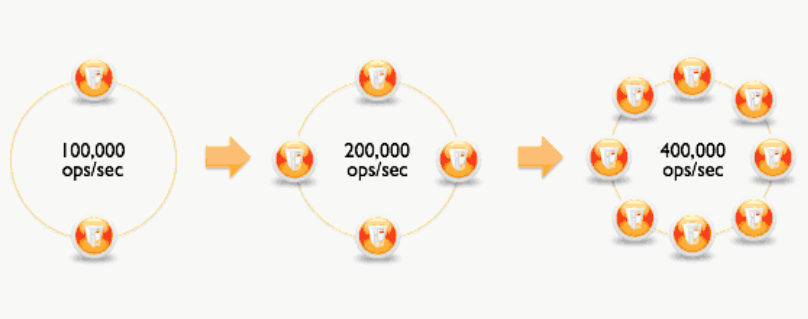
Cassandra는 선형 확장 성을 제공한다.
Cassandra는 선형 확장성을 제공한다. 즉, 온라인에서 새 노드를 추가하기만하면 용량을 쉽게 추가할 수 있다. 예를 들어, 2 개의 노드가 초당 100,000 개의 트랜잭션을 처리 할 수있는 경우 4개의 노드는 초당 200,000 개의 트랜잭션을 지원하고 8개의 노드는 초당 400,000 개의 트랜잭션을 처리한다.
Cassandra는 관계형 데이터베이스와 어떻게 다를까?
Cassandra는 처음부터 피어 투 피어 통신을 사용하는 분산 데이터베이스로 설계되었다. 모범 사례로 쿼리는 테이블 당 하나 여야한다. 이를 가능하게하기 위해 데이터는 비정규화된다. 이러한 이유로 클라이언트 측 조인을 응용 프로그램에서 사용할 수 있지만 테이블 간의 조인 개념은 존재하지 않는다.
'IT > Knowledge' 카테고리의 다른 글
| [NATS] NATS 개념 정리 (22) | 2023.03.22 |
|---|---|
| 배치와 데몬의 차이 (36) | 2023.03.08 |
| JDBC / ODBC 차이 (10) | 2023.02.24 |
| DBeaver (11) | 2023.02.23 |
| L4 스위치란?(23.02.16) (12) | 2023.02.17 |



댓글