반응형

Apache Kafka 에 대해서 알아보려고 한다.
카프카(Kafka)는 2011년 미국 링크드인(Linkedin)에서 개발했다.
카프카 이전에는 다음 그림과 같이 모든 것들이 서로 연관되어서 결합력이 높았다.
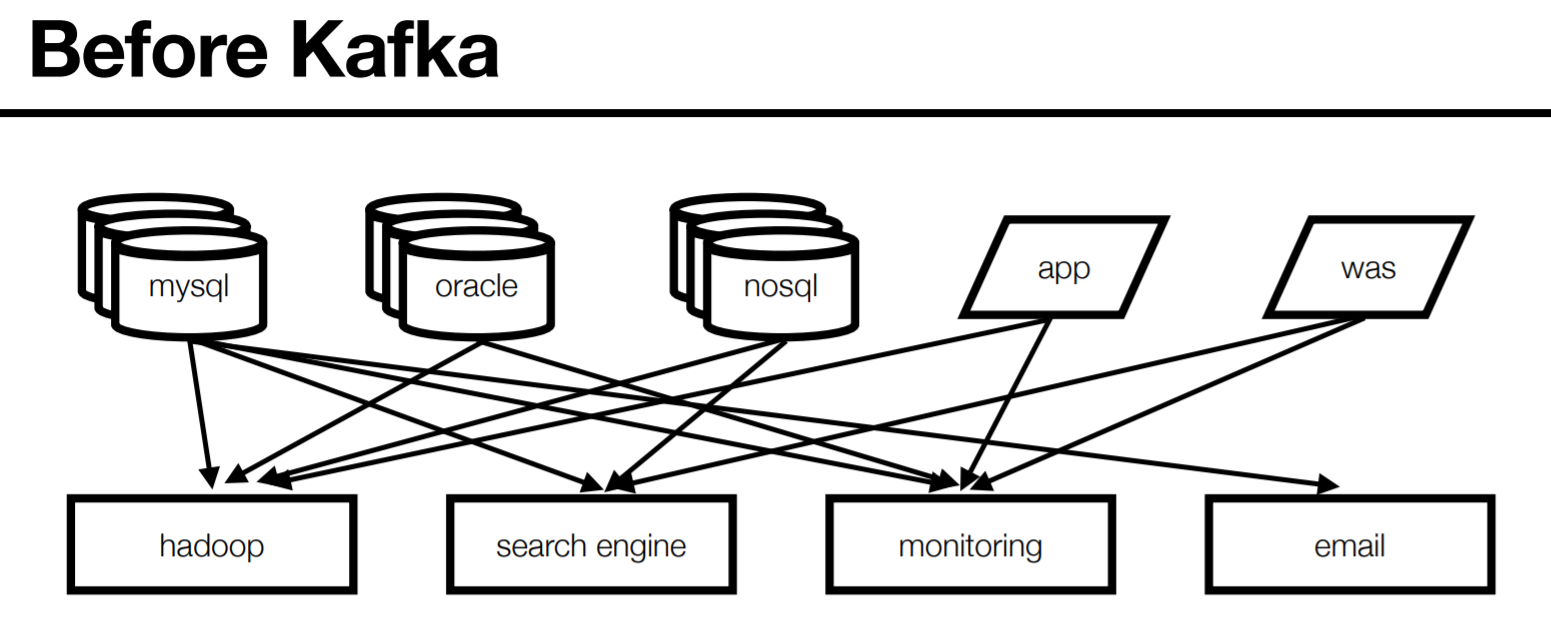
하지만 결합력을 낮추는 요즘 추세에서 처럼 이 방식 역시 확장성이 떨어지고 코드의 이해도와 복잡성이 어려워서 관리가 어려운것이 단점이었다.
그래서 나오게 된것이 카프카이다.
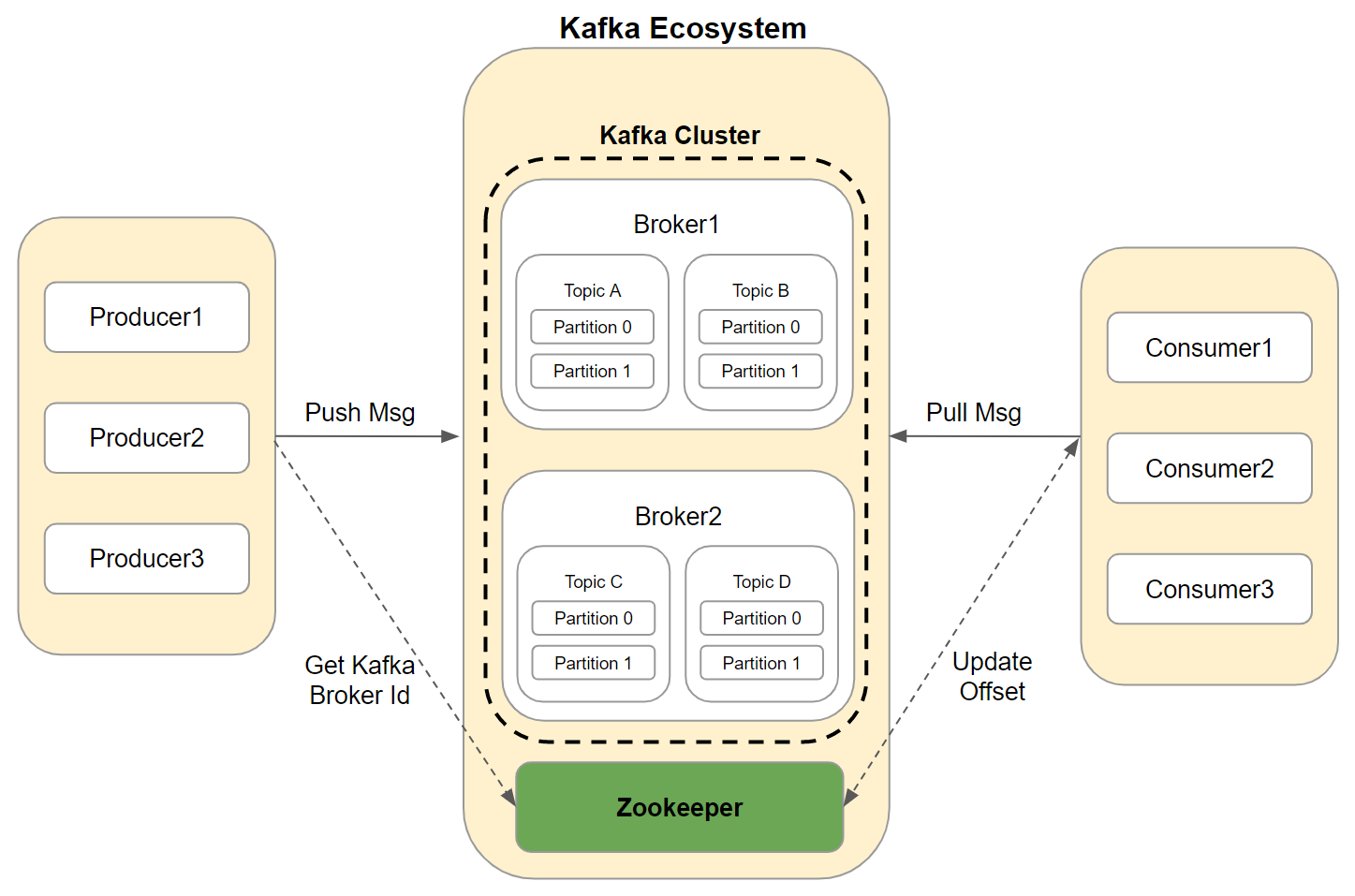
카프카는 위 그림처럼 기능이 단순해졌다.
각각 단어 설명을 하기 앞서 결론을 먼저 말하면 프로듀서에서 카프카로 메세지를 보내면 컨슈머에서 자기에게 해당하는 메세지를 당겨와서 받는
대규모 메시지 데이터를 빠르게 처리하도록 개발된 메시징 플랫폼
이다.
용어는 producer / consumer / broker / topic / partition / zookeeper 에 대해서만 알고 있으면 된다.
- producer
- 메시지를 만들어서 카프카 클러스터에 전송한다.
- 메시지 전송 시 Batch 처리가 가능하다.
- consumer
- 카프카 클러스터에서 메시지를 읽어서 처리한다.
- 메세지를 Batch 처리할 수 있다.
- 한 개의 컨슈머는 여러 개의 토픽을 처리할 수 있다.
- 메시지를 소비하여도 메시지를 삭제하지는 않는다. (Kafka delete policy에 의해 삭제)
- 한 번 저장된 메시지를 여러번 소비도 가능하다.
- broker
- 실행된 카프카 서버를 말한다.(프로듀서와 컨슈머는 별도의 애플리케이션으로 구성되는 반면, 브로커는 카프카 자체)
- 메시지를 저장하고 관리하는 역할
- topic
- 각각의 메시지를 목적에 맞게 구분할 때 사용한다. (결국 이 토픽에서 프로듀서의 메세지를 어느 컨슈머에게 줄지 정함)
- 메시지를 전송하거나 소비할 때 Topic을 반드시 입력한다.
- Consumer는 자신이 담당하는 Topic의 메시지를 처리한다.
- 한 개의 토픽은 한 개 이상의 파티션으로 구성된다.
- partition
- 분산 처리를 위해 사용된다.
- Topic 생성 시 partition 개수를 지정할 수 있다. (파티션 개수 변경 가능. *추가만 가능)
- 파티션이 1개라면 모든 메시지에 대해 순서가 보장된다.
- 파티션 내부에서 각 메시지는 offset(고유 번호)로 구분된다.
- 파티션이 여러개라면 Kafka 클러스터가 라운드 로빈 방식으로 분배해서 분산처리되기 때문에 순서 보장 X
- 파티션이 많을 수록 처리량이 좋지만 장애 복구 시간이 늘어난다.
- zookeeper
- 분산 애플리케이션 관리를 위한 코디네이션 시스템
- 분산 메시지큐의 메타 정보를 중앙에서 관리하는 역할
Kafka 특징
- 디스크에 메시지를 저장해서 영속성(persistency)를 보장
- 프로듀서와 컨슈머를 분리하고 멀티 프로듀서와 멀티 컨슈머를 지원
- 프로듀서와 컨슈머 모두 배치 처리가 가능해서 네트워크 오버헤드를 줄일 수 있음
- 높은 성능과 고가용성과 확장성을 가짐
- 메시지 보장 여부를 선택할 수 있음
Kafka 활용
- 서비스간 결합도를 낮추기 위해 사용
- 모든 데이터를 한 곳으로 집중할 때 유리 (ex. 로그 통합, 실시간 접속 분석, 서버 모니터링)
- 실시간 스트리밍 서비스에 적합 (ex. 알림 전송 등)
- 대규모 서비스와 배치 시스템에 적합
- 트래픽의 변화가 큰 곳에서 유용
반응형
'IT > Knowledge' 카테고리의 다른 글
| 라우팅 이란? (32) | 2022.07.10 |
|---|---|
| OLTP, OLAP (22) | 2022.07.09 |
| SAGA 패턴 (45) | 2022.07.05 |
| 클라우드 vs 코로케이션 차이 (58) | 2022.07.04 |
| CQRS 패턴 (40) | 2022.06.29 |



댓글