반응형
저번 포스팅에서는 페이지에서 글을 뭉텅이로 한번에 가져오는것을 연습하였고,
그 뭉텅이에서 각각 별개로 데이터를 가져오는것 까지 진행을 해볼것이다.
저번 포스팅을 잘 따라왔다면 현재 ul tag부분까지 가져왔을텐데 ultag를 좀더 자세하게 살펴보도록 할것이다.
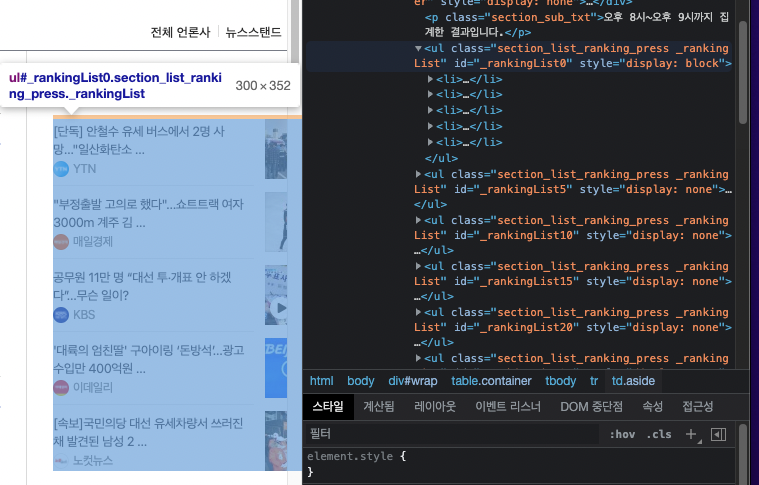
확대를 해보면 각각 li로 묶인것들이 5개가 들어가있고 때마침 글을 보니 5개가 있다.
저 li에 마우스를 각각 가져다 대면
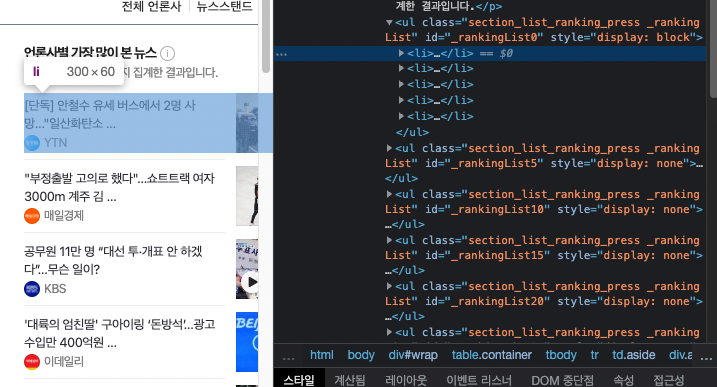
하나의 기사를 가리키고 있다.
그렇다 이 하나하나의 제목값이나 내용들을 반복문을 통해서 가져오면 된다.
저번에 가져온 ultag에서 li태그들을 먼저 가져온다.
litags = ultag.find_elements_by_tag_name('li')
litag들을 가져올것이라서 복수형으로 s를 붙여서 변수명을 만들었고,
저번 ultag에서 tag_namedl li인것들의 elements 를 찾아서 li tags로 묶어주고
이제 하나하나 li를 보니까 그 li가 사진처럼 a 태그로 묶여있다. 그리고 그 안에는 div class가 list_text 있다.
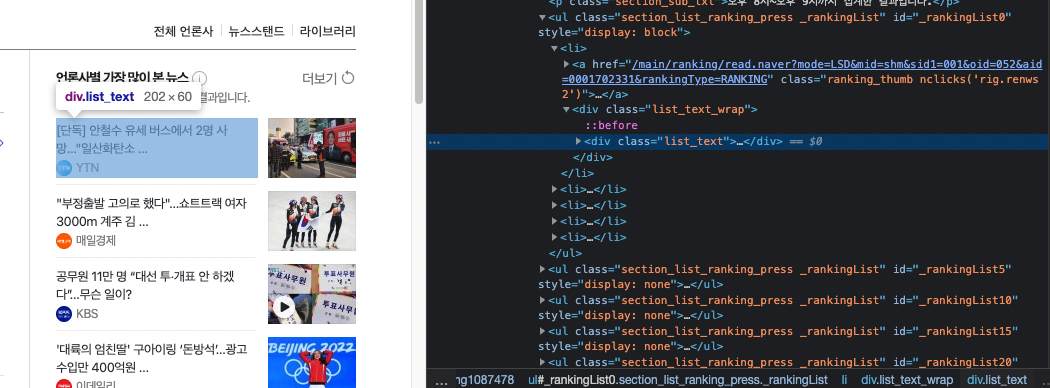
그럼 코드로 풀어내보면 litags 에서 하나하나의 litag를 가져오고 그 litag안에서 class name이 list_text를 찾아서 변수에 저장을 하고 출력을 하면 된다.
for litag in litags:
atag = litag.find_element_by_class_name('list_text')
print(atag.text)
그렇게 하면 아래처럼 제목만 글을 가져올수가 있게 된다.

여기서 추가적으로 자신이 원하는 텍스트가 있는 제목만 가져올수도 있게 코드를수정할수도 있다.
다음 포스팅에서는 단지 뉴스 페이지가 아닌 네이버에 검색을 하고 검색 결과에서 내가 필요한 정보의 제목만 가져올수 있는 코드를 추가적으로 짜보도록 할것이다.
반응형
'IT > Python' 카테고리의 다른 글
| python 크롤링 part.6 (31) | 2022.02.23 |
|---|---|
| python 크롤링 part.5 (26) | 2022.02.22 |
| python 크롤링 part.4 (46) | 2022.02.21 |
| python 크롤링 part.3 (47) | 2022.02.20 |
| python 크롤링 part.1 (59) | 2022.02.18 |




댓글