이번 포스팅은 검색 결과나 카페 등에서 데이터를 가져올 경우 페이지를 이동하며 데이터를 수집해야할 경우가 있을수도 있다.
그럴 때 사용할수 있는 페이지네이션 처리 적용 방법을 다뤄볼것이다.
즉 , 페이지를 순회하며 데이터를 수집하는 실습을 해볼것이다.
저번 포스팅에 있던 중고나라 데이터 수집에서 iframe 페이지 까지 들어오는것은 완료가 되었다는 기준으로 이어서 설명을 하도록 할것이다.
먼저 첫번째는 페이지를 1,2,3,4,5...다음,11,12 넘기면서 데이터를 가져 와보고
다음은 무한 스크롤이 있는 페이지에서도 스크롤을 내리면서 데이터를 가져와 볼 것이다.
일단 공통 코드는 저번포스팅 까지 했었던 아래와 같다.
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome('./chromedriver')
driver.get('https://cafe.naver.com/joonggonara')
elem = driver.find_element_by_id('topLayerQueryInput')
elem.send_keys('맥북')
elem.send_keys(Keys.ENTER)
time.sleep(1)
iframe = driver.find_element_by_id('cafe_main')
driver.switch_to.frame(iframe)
다음에 원래는 저번포스팅에서 했던 xpath를 통해서 값들을 가져올 것인데,
그 전에 어떻게 값을 가져올지, 어떤 작업을 수행할지를 먼저 생각해보자.
페이지 이동 버튼
일단 1페이지는 저번포스팅 처럼 그대로 가져오고 이어서 수행하는것은 사진에서 아래의 1 ~ 10 이나 다음을 누르고 다시 값들을 가져오게 된다.
똑같은 작업이 이루어질 예정이니 제목을 긁어오는 작업은 반복문으로 뺄 것이다.
그리고 아래 1 ~10 의 페이지를 누르는것도 반복문으로 뺄 것이다.
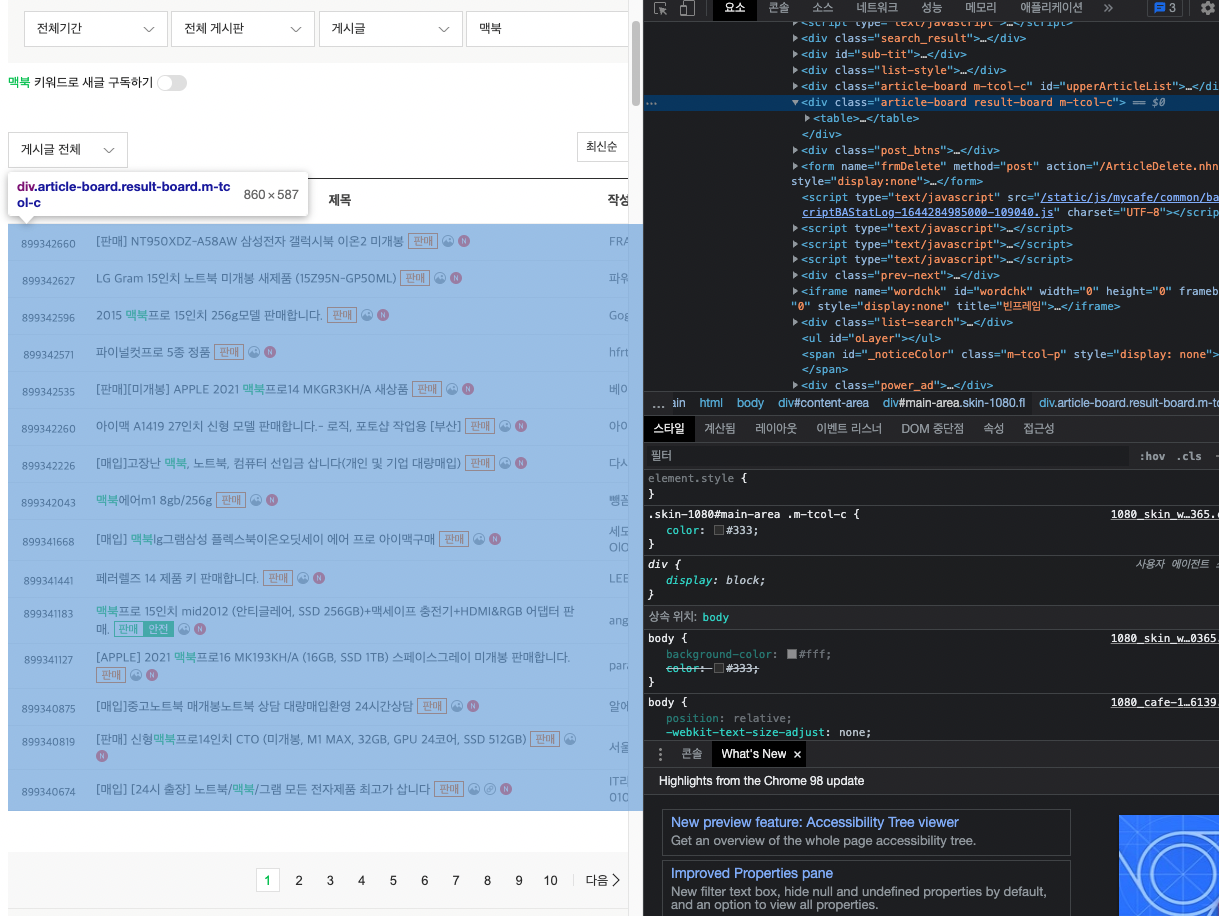
그럼 아래 1에서 10을 누르는 버튼이 뭔지, 그리고 다음을 누르는 버튼이 뭔지 확인 해보도록 한다.
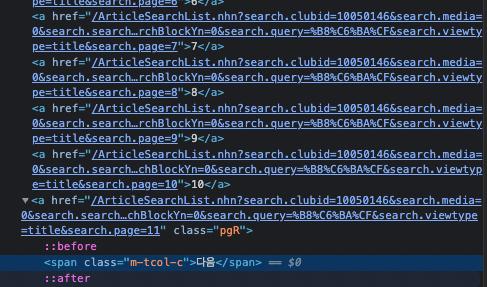
확인을 해보니 1에서 10은 a 태그로 묶여있고 다음은 pgR 이라는 클래스 이름으로 되어있다.
그럼 끝났다 코딩을 해보도록 하자.
일단 1페이지 시작이니 나는 시작을 2에서부터 20 페이지 까지 가져올것이다.
그리고 한페이지에 제목을 다읽으면 2에서 부터 20까지 버튼을 누르는데 그 메서드는
find_element_by_link_text('2') 을 사용해서 2페이지 갈때는 이 함수를 사용하게 될것이고,
다음을 누르는것은 find_element_by_class_name('pgR') 을 사용할 것이다.
그리고 다음은 반복되는 순서가 10배수보다 1이 큰 경우에(11,21,31,41....)만 누르게 할 것이다.
코드는 다음과 같아진다.
for i in range(2,20):
articleboard = driver.find_elements_by_class_name('article-board')
trtags = articleboard[1].find_elements_by_xpath('./table/tbody/tr')
for tr in trtags :
article = tr.find_element_by_class_name('article')
print(article.text)
if i%10 == 1:
driver.find_element_by_class_name('pgR').click()
else:
driver.find_element_by_link_text(str(i)).click()
time.sleep(1)
중간중간 페이지 로딩이 늦어질수도 있는것을 대비하여 time으로 1초씩 delay를 줬다.
무한스크롤 페이지
페이지를 넘기는 형식도 있지만 무한 스크롤로 한페이지에 모든 로딩을 해야할 경우도 있다.
그럴 경우엔 execute_script 함수를 사용하여 자바스크립트를 통해서 스크롤을 내리라고 명령을 날려준다.
처음부터 로딩이 무한으로 되는 페이지면 상관이 없는데 대부분 아키텍쳐들이 한번에 모든 데이터를 끌고오지 않고 보이는 부분의 값들만 끌고오고 스크롤이 내려갈시 다음 데이터들을 가져오기에 스크롤을 내려주는 작업을 진행해야한다.
간단하다.
특정 시간동안 반복을 해도 되고 while 반복문을 통해서 무한으로 하는것은 자유이지만
이 메서드를 사용해야한다는것만 알고가면 된다.
driver.get('https://www.naver.com')
driver.execute_script('window.scrollTo(0,2000);')
이렇게 사용을 해보면 네이버 창에서 2000 point 까지 내려가는것을 볼수 있다.
만약 화면이 2000까지 안된다면 최하단을 보여준다.
그리고 데이터를 가져오는 부분은 적절히 반복문으로 잘 감싸주면 무한 스크롤 페이지 역시 간단하게 구현이 된다.
'IT > Python' 카테고리의 다른 글
| 특정 파일 리스트 가져오기(listdir) (59) | 2022.07.28 |
|---|---|
| python 크롤링 part.6 (31) | 2022.02.23 |
| python 크롤링 part.4 (46) | 2022.02.21 |
| python 크롤링 part.3 (47) | 2022.02.20 |
| python 크롤링 part.2 (30) | 2022.02.19 |



댓글